Taking Back My Own Data
Image this scenario - you're just starting to make a lifestyle change and you want to track progress. So you install an app to track your progress - job jobbed! But what if you want to surface that data elsewhere such as a custom made dashboard...

The All Too Familiar Problem
Image this scenario - you're just starting to make a lifestyle change and you want to track progress (might be tracking weight, goals, calories, distance run etc). So you install an app to track your progress - job jobbed! But what if you want to surface that data elsewhere such as a custom made dashboard that tracks calories consumed vs weight. What if you want to cross reference the impact your weight has on how fast you've been running in your training sessions. Is there an easy way to get at this data?
Being someone who works with software and a keen runner who's also invested in making healthier life choices, I've been frustrated by some platforms and their reluctance to make your data accessible via an API that you can easily consume. The manufacturers of my bluetooth scales 'Renpho' are no exception to this.
No API? No Problem!
As I mentioned, I'm a software engineer and I'm used to working around problems. I decided that if Renpho wouldn't make it easy to get regular access to my own data via an API, then I'd take it myself!
Options
Looking into my options I narrowed my choices down to 3 potential routes for gathering the data
1) Utilising something already built like open scale. This is actually a fairly sensible option as this is a well supported open source project. The downside to this option was that its all saved to CSV and I'd need another companion app to sync it to MQTT or Google fit etc.
2) Reverse engineer the Renpho Health apk and add some code to send the data to my services. The downside to this is that I'm not a mobile or android engineer by default and this would be potentially much more time consuming for an already busy dad to figure out.
3) Develop something to scan an image of the data from the app and transform it into something simple like JSON which I can send to a service I own.
The Choice
I opted for choice number 3, because it:
a) Sounded the easiest
2) Meant I got to play around with something I've never done before (spoiler it's pytesseract)
iii) Would fit in easiest with my current home lab set up
The Criteria
I narrowed my acceptance criteria for the task to a list of bullet points:
- It needed to be low friction
- It needed to create data in an easy to reuse format like JSON
- It needed to be reliable
- It needed to be a service I could access without being on my home network
- I wanted to be able to get the data into Grafana
With these items in mind I decided that it would be nice if I could utilise the existing android renpho health app to take a photo of the data the scales already give me, process the photo, read the data and output a JSON object. Easy right?
The Tech
Language and packages
I did some research into OCR and quickly came across python, opencv and pytesseract as a commonly utilised combination to achieve this goal. Despite there being a lot of documentation on this, it wasn't always smooth sailing!
Entrypoint
In terms of making this accessible from anywhere, despite the fact that I have a custom domain and some home lab servers set up - I didn't fancy setting up custom authentication to allow data to be sent to my internal systems. In the past I've utilised telegram bots as entry points to communicate with services I host locally and you can restrict which chats they are authorized to take commands from. Given that you can also send images to these bots, it seemed like a perfect fit.
Hardware
To run the service that would be polling for updates picked up by the bot in the telegram chat I decided to utilise my existing setup. I have a couple of app servers running at home with my own hosted gitlab and gitlab runners that I regularly use to deploy docker containers.
Storage and Graphs
I wanted to display the data in a nice format utilising Grafana but in order to do that I needed a database. Since I already have this for other graphs in Grafana I decided to utilise InfluxDB which is a timeseries database.
The Method
As mentioned earlier it was no easy feat getting pytesseract to read the data from the image. You see, an image that is simple for us to read is not so simple for a computer to read. We take for granted that we can easily distinguish edges of letters, pick up contrast between colours and pick up different fonts without having to learn from scratch.
This is where opencv comes in...
img = cv2.imread(image_path)
resized_img = cv2.resize(img, None, fx=3, fy=2.5,interpolation=cv2.INTER_LANCZOS4)
gray = cv2.cvtColor(resized_img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3), 0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3))
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=1)
invert = 255 - opening
The snippet of code you can see above is some simple image processing that will enlarge the dimensions of the image, convert the image to greyscale, sharpen it up and level out the contrast to give the pytesseract package the best chance of picking up the numbers/text in the image. Believe it or not I actually spent an entire day tweaking these values and it still wasn't perfect!
In order to give pytesseract the best chance, I did a couple of things:
- Enlarged and slightly stretched the image. Making the image slightly wider than it is tall seemed to help consistently getting 5s to be 5s and not 9s
- Split the image up into 3 columns. As you can see from the image below the weight data is in 3 clearly equal-ish spaced columns and for some reason splitting it up into individual columns seemed to make it easier for pytesseract to pick up the data one item at a time instead of mixing them
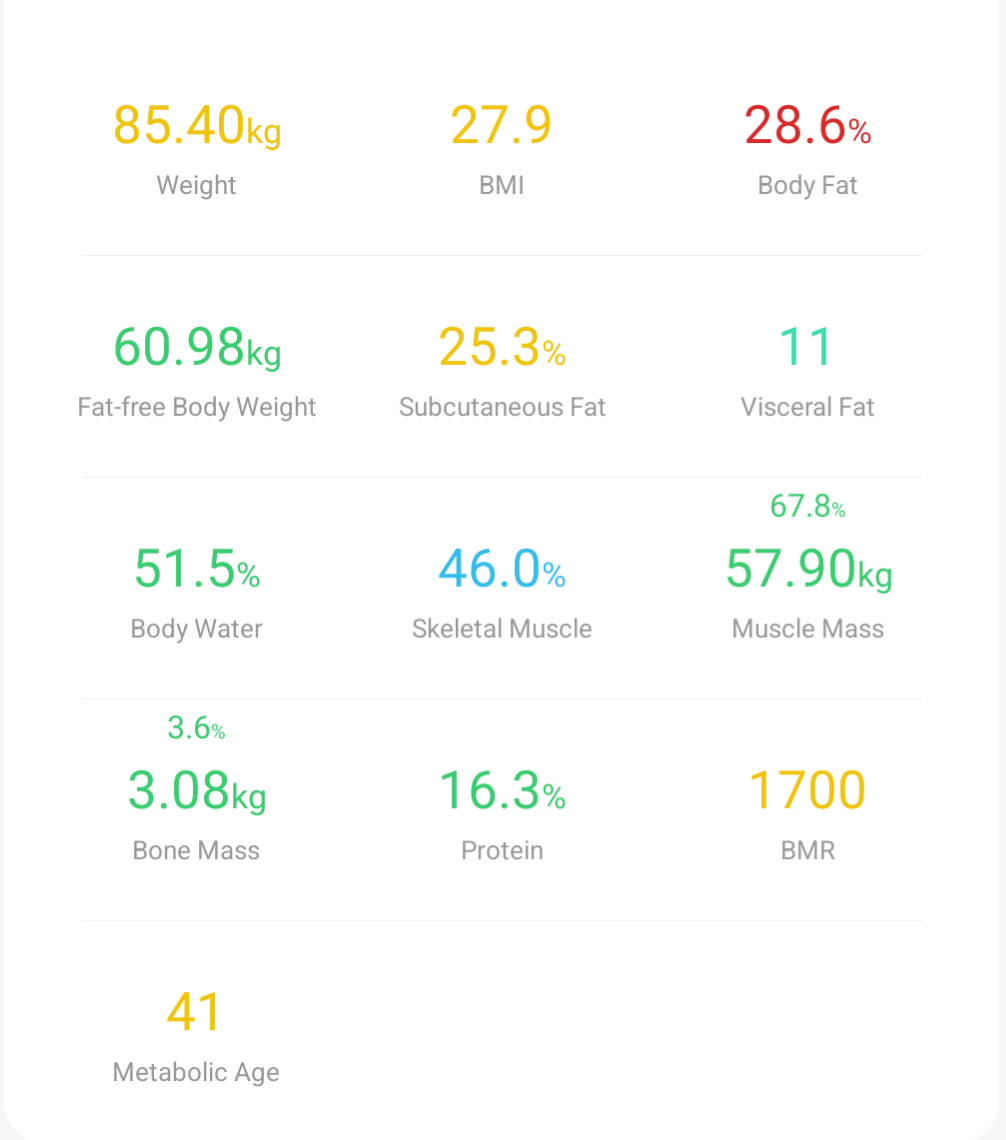
Once I had the data I next needed to get this into some form of useable data. I found that the output text regularly came with slightly unpredictable spacing between the numbers, but what was consistent was the split between the numbers and text that followed. Pattern recognition is of course a job for regex and so I removed the spaces from the output text and crafted a nice JSON object with the data captured from each of the regex groups
More Problems...
You'd think that at this stage everything is all good and we can just send the data to InfluxDB:
Photo sent to app via telegramImage read by pytesseractData transferred to JSON format- Transfer data to InfluxDB via the Influx API
WRONG!
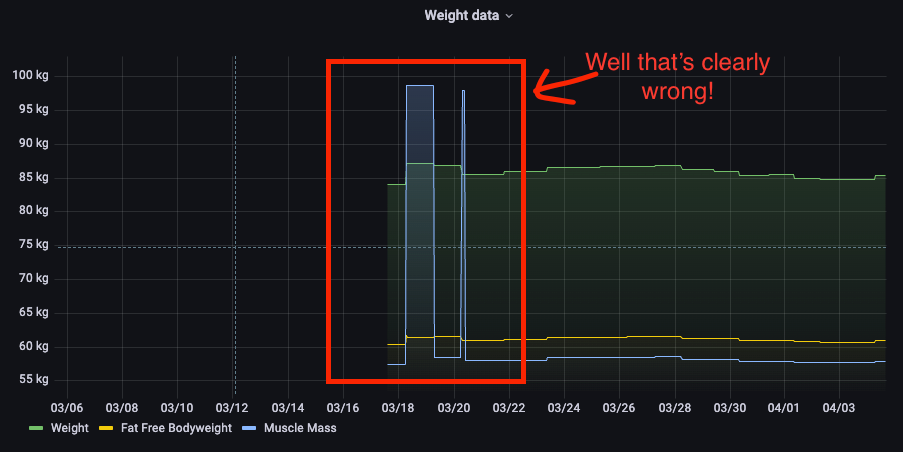
Upon testing I found that despite multiple tweaks it was hard to get the character recognition software to accurately pick up the difference between 5s and 9s or 1s and 7s.
Short of training the model to recognise a specific font and then rebaking the image into my pipeline (yuk!) I needed a way to preview the data and correct it if necessary. Again I needed this to be light touch or I'd be less likely to actually use this bot.
The solution for this that I settled on was to store the JSON object on the server in an overwritable file. It'll be populated when the data is first extracted and then sent to the user, the user in the chat can then review it and post any changes by simply sending the number line(s) they want to correct and the correction value (see below)
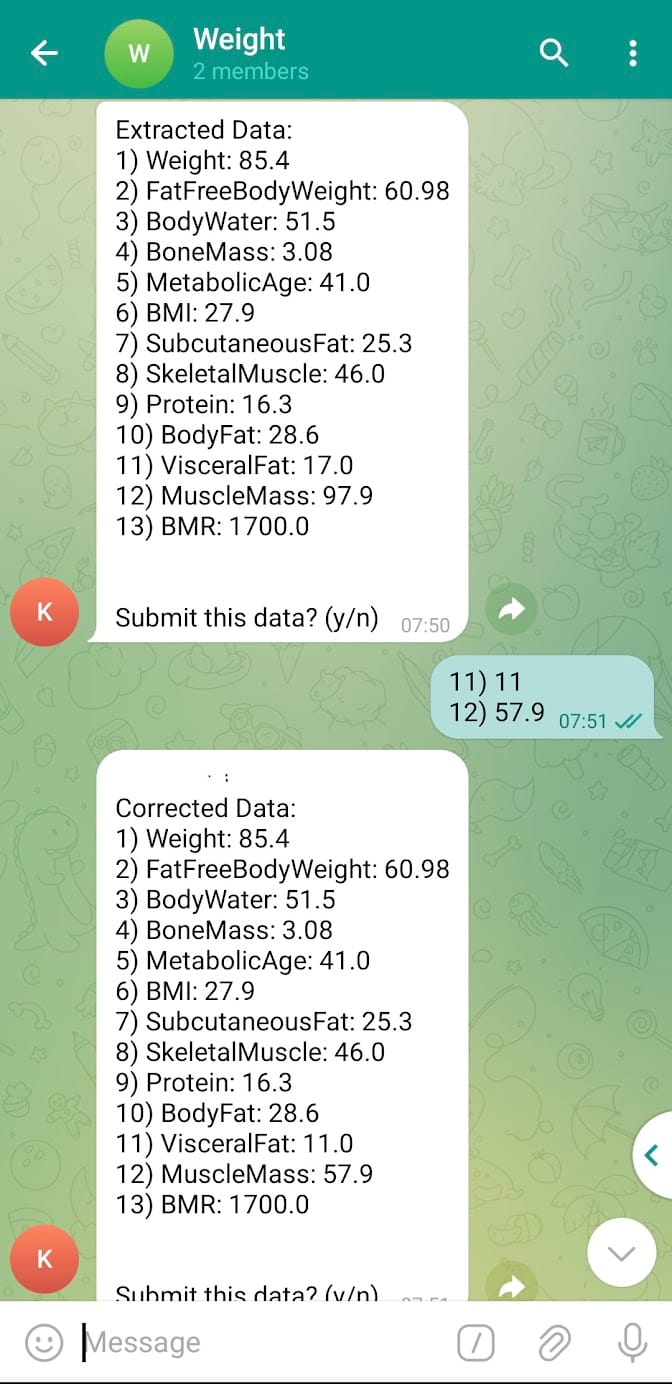
This will update the JSON file and again prompt the user with the corrected data and ask if they want to submit it. If the user selects (y/Y) then it'll submit the data, (n/N) deletes the JSON file and does not submit the data.
Conclusion
All in all I'm happy with my little homemade solution to getting access to my own data. I can now send this data anywhere I want and use it for my own purposes. The project was a fun little experiment into a language and packages I don't regularly get to utilise.
It's a little janky sure and I could definitely improve it but I find that it's also a good example of how thinking like an engineer can give you solutions to problems in ways that are unconvential. It's also comforting to me that if you can see data you want to take ownership of, there's likely some way or other to extract it for yourself and present it in a nicer format if you so wish.